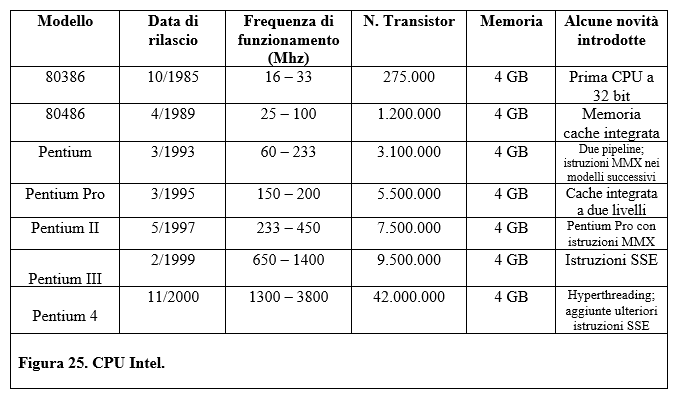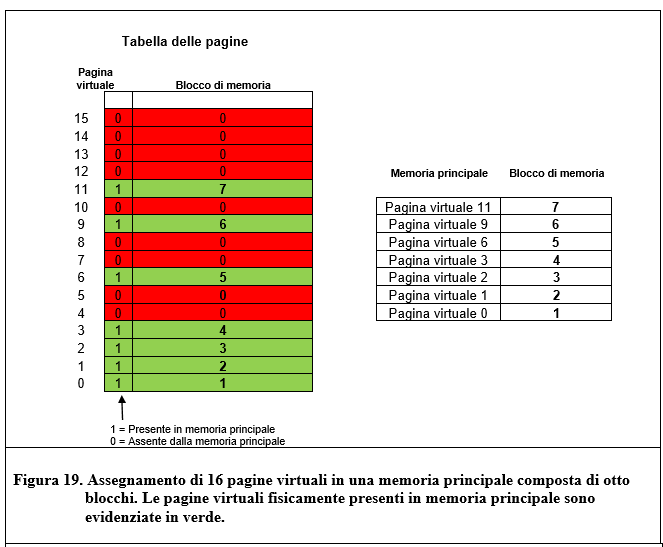
La tecnologia, sempre più avanzata, continua ad apportare migliorie alle prestazioni dei microprocessori. Sul mercato vengono immessi processori sempre più potenti. Ogni architettura, però, presenta un limite tecnologico insuperabile.
Il parallelismo, tecnica che consiste nell’eseguire due o più operazioni contemporaneamente, aumenta in modo notevole le performance dei moderni processori e può essere implementato in due differenti forme: parallelismo a livello di istruzioni e parallelismo a livello di processore. In questa sezione si esamina il parallelismo a livello di istruzioni: la pipeline.
La lettura delle istruzioni dalla memoria centrale rallenta il lavoro del microprocessore; ma i calcolatori sono in grado di prelevarle in anticipo, in modo che esse siano subito disponibili nel momento in cui devono essere processate.
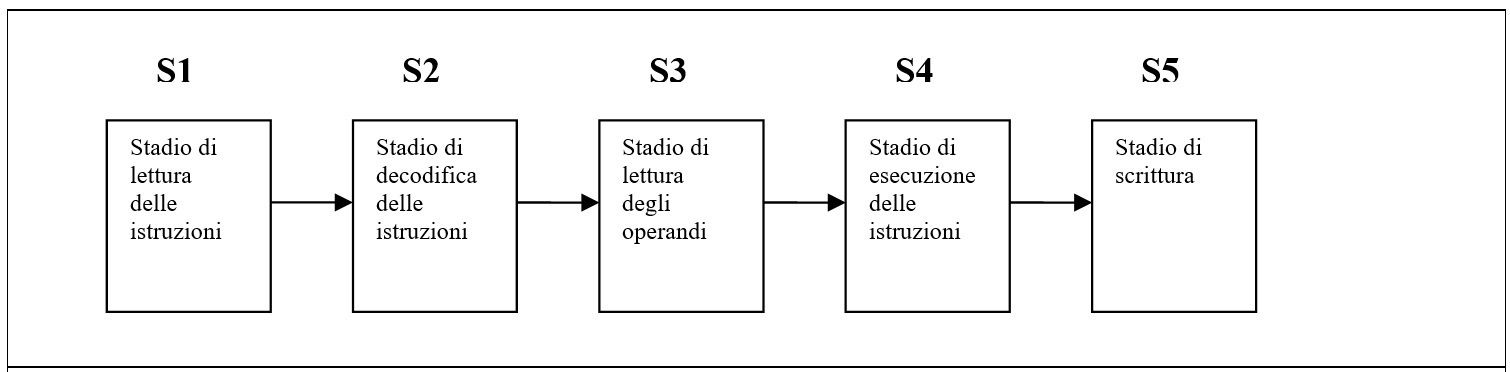
Con la tecnica della pipeline, l’esecuzione di una istruzione viene divisa in più fasi, ognuna delle quali è gestita da un’unità funzionale dedicata, in modo che il tutto possa avvenire in parallelo. Le varie fasi, in cui è divisa un’istruzione, sono definite anche stadi.
Supponiamo di avere un processore che implementa una pipeline a cinque stadi. Vi è, comunemente, uno stadio di lettura di un’istruzione, un secondo stadio di decodifica, un terzo di lettura degli operandi, un quarto stadio di esecuzione delle istruzioni e infine lo stadio di scrittura.
Analizziamo il lavoro di una pipeline.
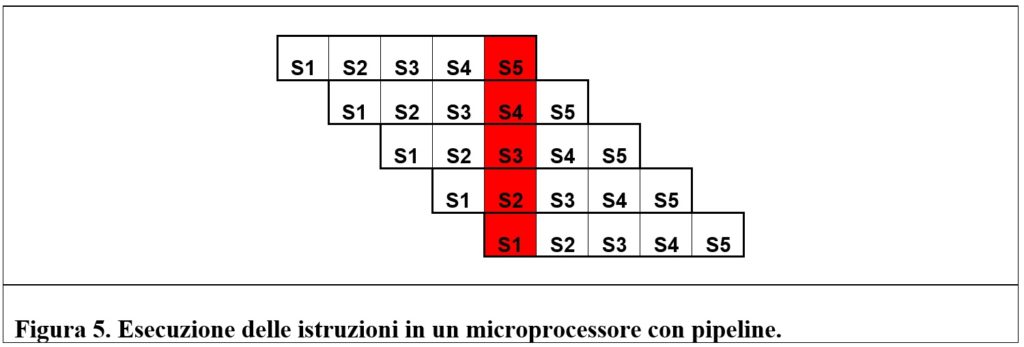
Primo ciclo di clock. L’istruzione A viene prelevata dalla memoria.
Secondo ciclo. Il secondo stadio decodifica A; contemporaneamente il primo stadio legge dalla memoria l’istruzione B.
Terzo ciclo. Il terzo stadio legge gli operandi dell’istruzione A; contemporaneamente B viene decodificata nel secondo stadio; una terza istruzione, C, viene letta dalla memoria dal primo stadio.
Quarto ciclo. L’istruzione A viene eseguita dal quarto stadio; quello precedente legge gli operandi dell’istruzione B. C viene decodificata nel secondo stadio mentre una quarta istruzione, D, viene letta dal primo.
Quinto ciclo. L’ultimo stadio scrive il risultato dell’istruzione A mentre gli altri stadi lavorano sulle altre istruzioni.
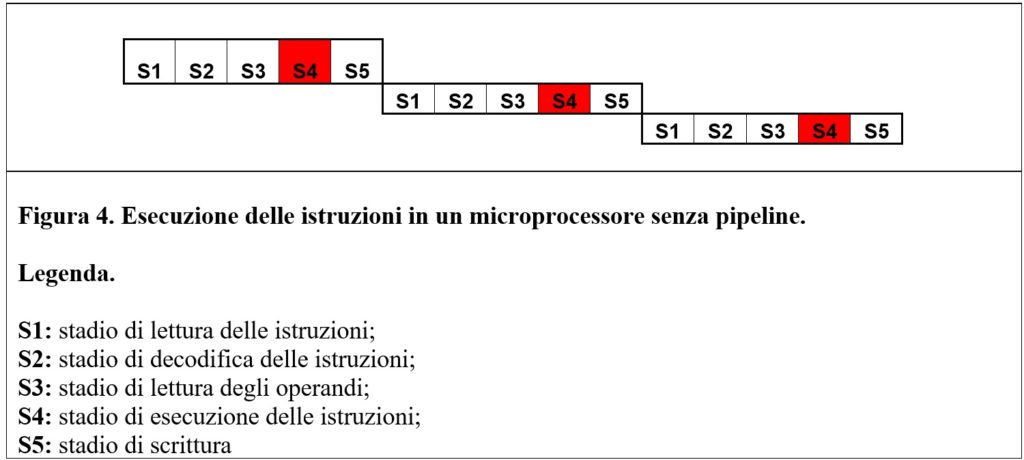
L’elaborazione di dati non ancora disponibili e i salti condizionati causano complessità all’implementazione di una pipeline.
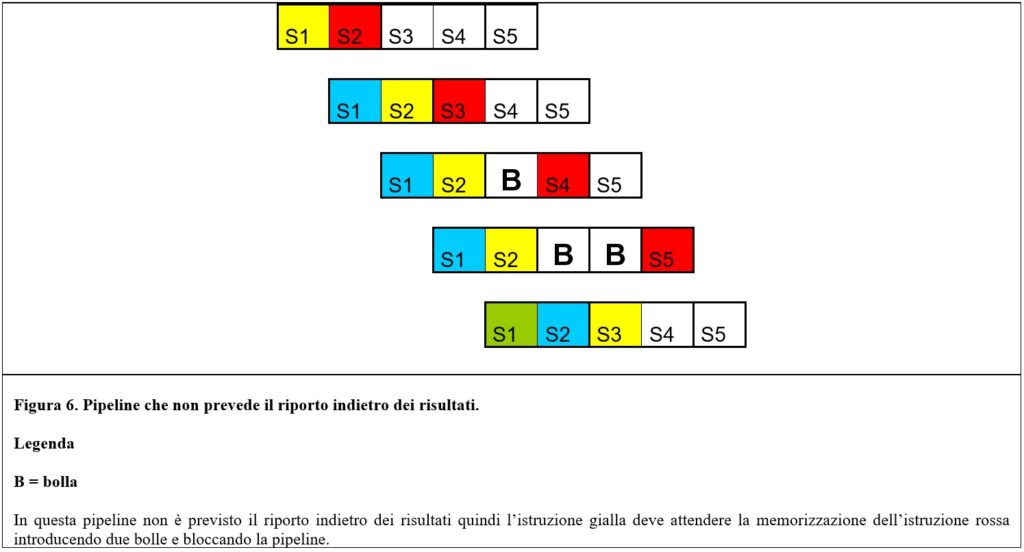
Il primo problema è causato dal lavoro parallelo delle unità. Per esempio: supponiamo che un microprocessore con pipeline debba eseguire il codice seguente:
A + B = C (istruzione rossa);
C – 1 = D (istruzione gialla).
La CPU deve eseguire due istruzioni in parallelo. L’istruzione rossa deve prelevare i valori delle variabili A e B, sommarli e inserire il risultato nella variabile C. L’istruzione gialla deve sottrarre alla variabile C una unità e memorizzare il valore ottenuto in D. Quest’ultima istruzione (C) non potrà essere eseguita (si verifica uno stallo nello stadio S3) fino a quando non sarà disponibile in memoria (registro) il valore della variabile C. La seconda operazione (gialla) si blocca per attendere il completamento della prima (rossa). Questo esempio viene rappresentato graficamente nella figura 6.
Con l’implementazione dei registri a doppia porta e l’ausilio di alcune tecniche (come ad esempio la predizione dei salti), si evita il blocco della pipeline. I registri a doppia porta sono in grado di portare i risultati, appena elaborati, alle istruzioni successive senza attendere il loro salvataggio in memoria.
Supponiamo, ora, che il codice da eseguire sia il seguente:
A + B = C (istruzione rossa);
C – 1 = D (istruzione gialla);
E + 2 = F (istruzione celeste);
L + 3 = G (istruzione arancione);
H + 3 = I (istruzione verde).
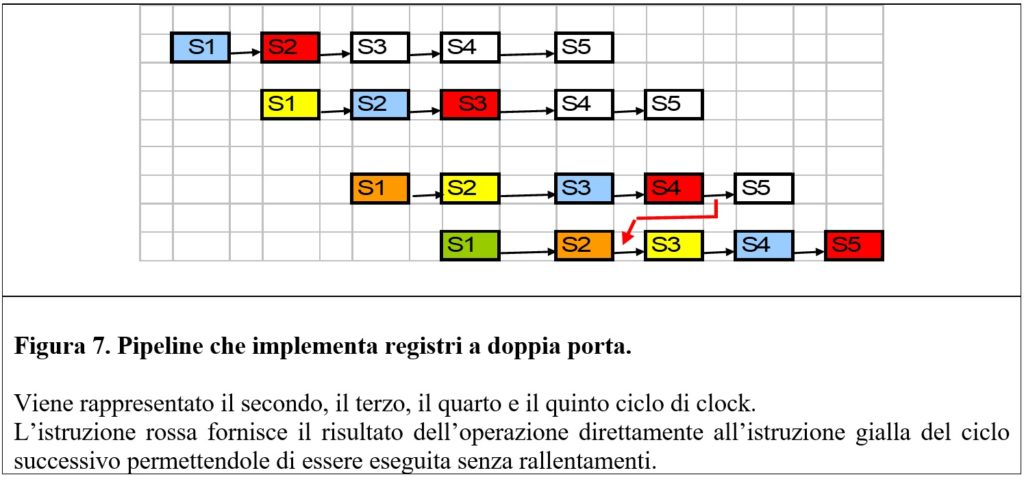
Per evitare stalli della pipeline vengono eseguite, all’inizio, due istruzioni indipendenti: l’istruzione rossa e l’istruzione celeste.
Alla quarta fase del ciclo di clock (stadio S4 della pipeline) il risultato della prima istruzione (A + B = C) passa all’operazione gialla (C – 1 = D), che essendo al suo secondo ciclo di clock, è ancora nella fase di decodifica. Questo passaggio all’indietro dei risultati permette di eliminare gli stalli di elaborazione.
La tecnologia, sempre più avanzata, ha permesso di realizzare pipeline con molti più stadi rispetto al modello standard; di conseguenza ogni istruzione viene divisa in più sotto-istruzioni.
Con l’aumento del numero degli stadi, i progettisti sono riusciti ad incrementare la frequenza dei processori, dato che ogni stadio deve svolgere un’operazione più semplice e quindi di più facile elaborazione.
Sommario, Bibliografia e Sitografia
Vincenzo Barile
segue…