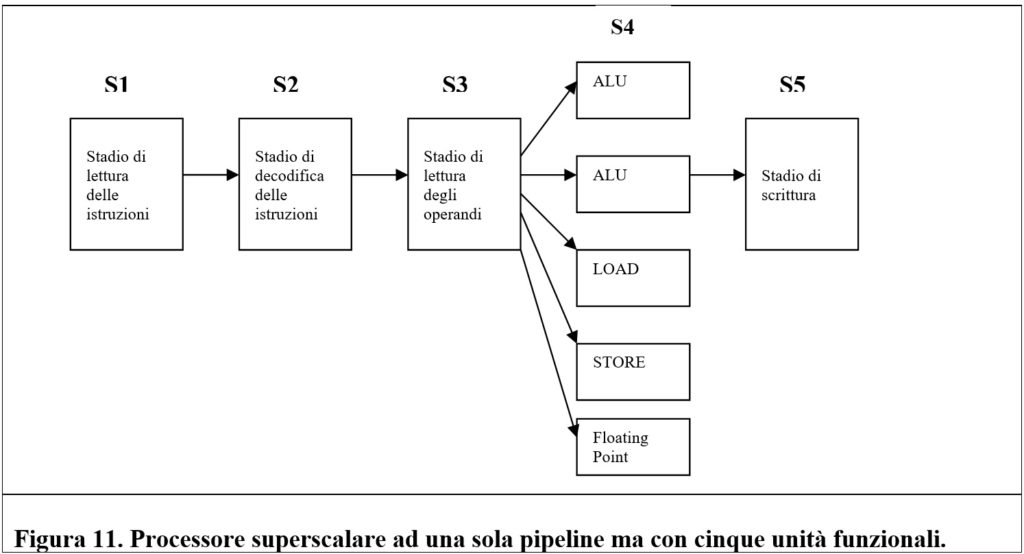
Nei microprocessori moderni è possibile integrare più pipeline che funzionano in parallelo: essi sono definiti superscalari.
Queste CPU supportano il calcolo parallelo su un singolo chip e permettono prestazioni superiori, a parità di clock, rispetto ad una CPU che non adotta tale architettura.
È possibile definire superscalare un processore in grado di avviare in esecuzione più di una istruzione in un singolo ciclo di clock.
Un processore superscalare, generalmente, si compone di diverse unità funzionali dello stesso tipo. Ad esempio, sono presenti numerose unità per il calcolo intero (ALU). Le unità di controllo si occupano di stabilire quali istruzioni possono essere eseguite in parallelo e di inviarle alle rispettive unità. L’architettura diviene così più complessa e richiede un notevole numero di transistor.
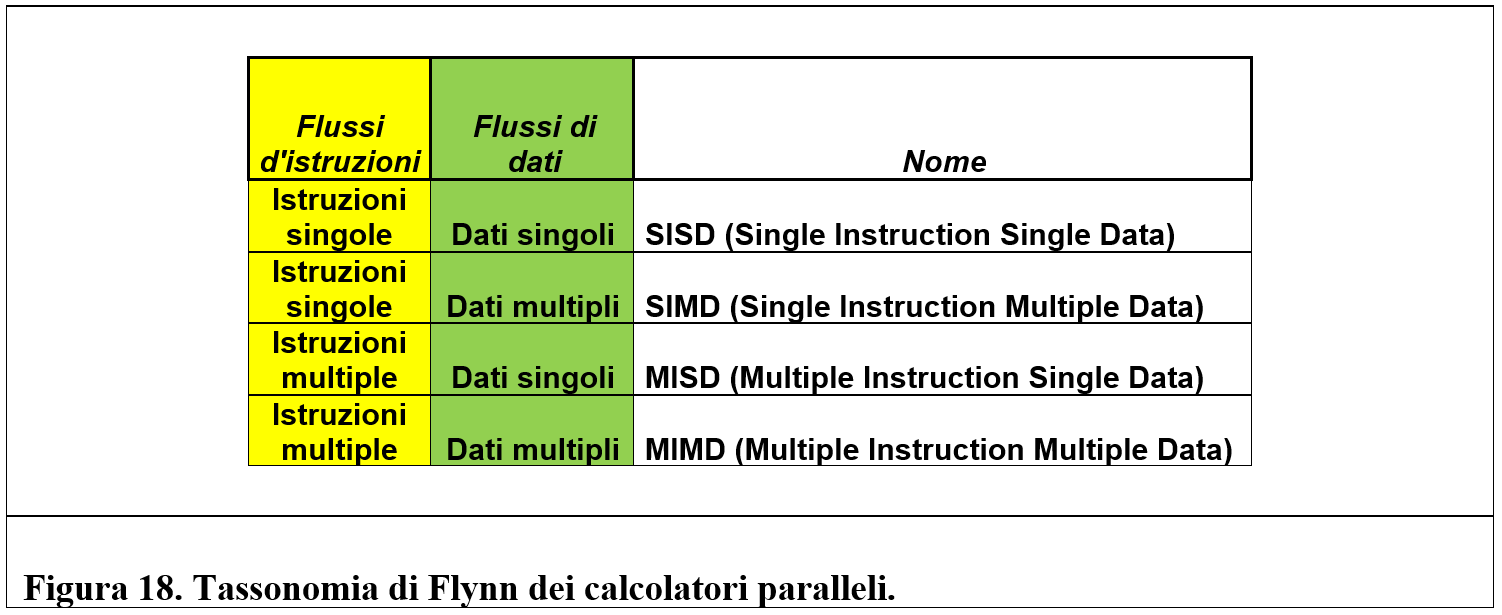
La figura 10 descrive una possibile configurazione di un processore superscalare con doppia pipeline.
Il primo stadio legge due istruzioni per volta e mette ognuna in una differente pipeline. Ogni pipeline può contenere la propria unità di ALU. L’esecuzione parallela implica che le istruzioni non devono generare conflitti sull’uso delle risorse (come ad esempio richiedere l’accesso contemporaneo ad un medesimo registro) o richiedere l’elaborazione di dati non ancora disponibili.
Le architetture superscalari trovano origine sulle macchine RISC, ragione per cui queste CPU erano di gran lunga più veloci dei CISC tra gli anni ’80 e ’90.
La Intel iniziò ad introdurre la tecnica della pipeline a partire dal processore 80486; anche se in realtà già nel processore 8086 esisteva una tecnica rudimentale di pipeline, con la quale la fase di fetch delle istruzioni era eseguita in parallelo con la fase di decodifica ed esecuzione. Un successore dell’80486, il Pentium, è dotato di una doppia pipeline a cinque stadi, denominate rispettivamente pipeline u e pipeline v. La prima, quella principale, è in grado di eseguire una qualunque istruzione del processore Pentium. La seconda è in grado di eseguire solo istruzioni semplici su interi o istruzioni semplici di tipo floating-point. Se le istruzioni prese in coppia non sono semplici o tra loro incompatibili la pipeline u esegue solo la prima; mentre la seconda fa coppia con l’istruzione seguente.
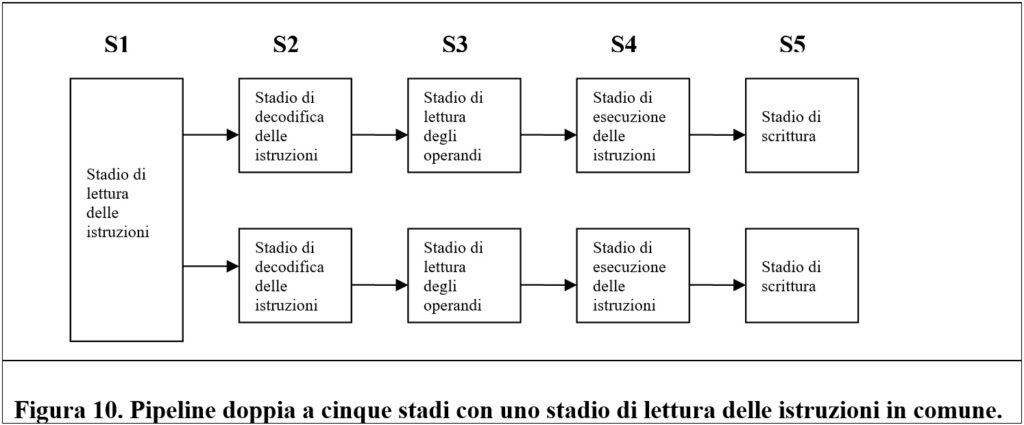
Esiste anche un altro approccio per realizzare processori superscalari. È possibile implementare una pipeline singola ma con unità funzionali multiple.
Questa idea di base è descritta dalla figura che segue.
Un ulteriore approccio per realizzare processori superscalari consiste nell’integrare più processori indipendenti (denominati core) in un singolo processore. Questo tipo di progetto non soltanto ingloba all’interno delle CPU più pipeline, ma prevede che le pipeline siano tra loro separate. Questo permette di eseguire contemporaneamente programmi diversi.
Un’altra soluzione vede una separazione logica, ma non fisica, della pipeline, mantenendo in comune i circuiti di controllo e di gestione permettendo di eseguire più thread in parallelo senza dover necessariamente incrementare le unità funzionali. La tecnologia del multithreading simultaneo, che sarà approfondita nel seguito, è basata su questa idea.
Quando ci troviamo di fronte ad un’architettura semplice le istruzioni vengono eseguite nell’ordine imposto dal programma o meglio nell’ordine in cui sono prelevate dalla memoria, ipotizzando che l’algoritmo di predizione delle diramazioni faccia ipotesi sempre corrette. Tuttavia, l’esecuzione ordinata delle istruzioni non sempre garantisce prestazioni ottimali a causa delle dipendenze tra istruzioni. Ad esempio, se una istruzione richiede di eseguire una somma tra i valori contenuti in due registri, e il risultato della somma serva come operando ad una divisione, è facile dedurre che le due operazioni non possono essere eseguite in parallelo senza generare conflitti.
Le istruzioni che richiedono un valore calcolato da una istruzione precedente non possono essere eseguite fin quando tale valore non sia disponibile. Tali situazioni sono denominate dipendenze RAW (Read After Write).
Nel tentativo di aggirare questi problemi è possibile eseguire in parallelo istruzioni che non hanno dipendenze, ponendole entro un buffer che alimenta le pipeline. Le istruzioni eseguite fuori ordine non creano errori di programma in quanto l’algoritmo di scheduling delle istruzioni provvede a ricostruirne l’ordine cronologico, rispettando l’ordine stabilito dal programma.
L’unità di decodifica, dopo aver decodificato una istruzione, deve decidere se mandarla o meno in esecuzione, analizzando lo stato di tutti i registri. Se l’istruzione corrente, ad esempio, richiede un registro il cui valore è utilizzato da un’altra istruzione precedente, quella corrente non può essere mandata in esecuzione.
La CPU tiene traccia dell’uso dei registri attraverso uno strumento denominato scoreboard (tabella dei punteggi). Questa tabella dispone di un contatore per ciascun registro che rappresenta il numero di istruzioni in fase di esecuzione che richiedono quel particolare registro come sorgente di un operando. Quando viene lanciata una nuova istruzione, di conseguenza, si incrementano le voci dello scoreboard. Viceversa, quando una istruzione termina, le voci vengono decrementate. Lo scoreboard, inoltre, contiene dei contatori per tener traccia dei registri utilizzati come destinazioni e registra l’uso delle unità funzionali per evitare che, al lancio di una istruzione, non vi siano unità funzionali disponibili.
Abbiamo già precisato che una istruzione non può essere lanciata se sussiste una dipendenza RAW. Esistono altri due tipi di dipendenze, meno gravi, generate principalmente da conflitti di risorse. Il primo tipo è una dipendenza di tipo WAR (Write After Read): una istruzione cerca di sovrascrivere un registro che una istruzione precedente non ha ancora terminato di leggere. Il secondo tipo di dipendenza è quella WAW (Write After Write), molto simile alla prima. Le dipendenze WAR e WAW possono essere evitate costringendo la seconda istruzione a salvare il suo risultato in un registro temporaneo.
In un processore superscalare che implementa l’esecuzione fuori ordine, quando una istruzione corrente accede ad un registro che non sia libero o che contenga un valore errato, la pipeline dovrebbe andare in stallo fino a quando il registro si libera o contenga il valore corretto. La situazione di stallo viene evitata implementando la ridenominazione dei registri. Con quest’ultima tecnica, la CPU dispone di numerosi registri fisici nascosti che vengono assegnati alle istruzioni quando servono dei registri che risultano già occupati. Ad esempio, in un dato istante un ipotetico registro R1 potrebbe essere assegnato a tre registri fisici nascosti che fingono di essere il registro R1 per le istruzioni che ne fanno uso, ed evitare così lo stallo della pipeline.
I programmi sono suddivisi in blocchi elementari. Ogni blocco è costituito da una sequenza lineare di istruzioni e non contiene al suo interno nessuna struttura di controllo. L’assenza di strutture di controllo all’interno dei blocchi elementari favorisce l’assenza di diramazioni. I blocchi elementari sono collegati tra loro da strutture di controllo.
La maggior parte dei blocchi elementari è di breve lunghezza. Ciò costituisce un problema in quanto non vi è al loro interno sufficiente parallelismo da poter sfruttare per ottimizzare le prestazioni. Per garantire efficienza è possibile anticipare l’esecuzione di una istruzione potenzialmente lenta, come una istruzione LOAD, un’operazione in virgola mobile o addirittura mandare in esecuzione una lunga catena di dipendenze, prima che si verifica una diramazione. La tecnica che consiste nell’anticipare l’esecuzione del codice prima di una diramazione è nota come slittamento. Quindi si mandano in esecuzione parti di codice prima ancora di sapere se saranno effettivamente richieste. L’esecuzione anticipata di parti del codice è definita esecuzione speculativa.
Implementare l’esecuzione speculativa non è semplice e bisogna affrontare notevoli problematiche di gestione.
Ad esempio, un problema è quello di non permettere alle istruzioni speculative di produrre risultati irrevocabili, dato che il codice eseguito potrebbe essere effettivamente non richiesto. Questo problema può essere risolto con la ridenominazione dei registri. Tutti i registri utilizzati dal codice speculativo vengono ridenominati. In questo modo vengono modificati solo i registri temporanei (nascosti) che non generano problemi se in ultima istanza il codice risulta non richiesto. Viceversa, se il codice eseguito risulta necessario viene fatta una copia dei registri nascosti nei registri di destinazione corretti.
Sommario, Bibliografia e Sitografia
Vincenzo Barile
segue…